spss29.0 mac版是一款專門為mac用戶提供的計數據分析新軟件,一般又稱為ibm spss statistics 29 mac,spss for mac 29,該軟件采用類似Excel表格的方式輸入與管理數據,且數據接口也較為通用,用戶可方便的從其他數據庫中讀入數據,并且spss還可以分布于通訊、醫療、銀行、證券、保險、制造、商業、市場研究以及科研教育等多個領域和行業,同時還具有易用性、靈活性和可擴展性,使用這款軟件就能夠幫助相關研究、分析人員輕松完成統計分析工作,成為做統計報表的好幫手。
除此之外,spss29.0軟件還擁有更智能的數據導入和導出功能,且可更加智能化的讀取和寫入Excel文件,可根據具有相同格式的值的指定百分比確定列的數據格式,甚至還具有強大的分析技術和能力,可以節省時間,幫助你在數據中快速和容易地找到新的想法,有需要的朋友歡迎前來本站免費下載體驗。
ibm spss statistics 29 mac新特性
一、彈性網(Elastic Net)
新的線性彈性網絡擴展過程估計一個或多個自變量上因變量的正則化線性回歸模型。該圖表示該過程的示例輸出。
二、套索(Lasso)
新的線性套索擴展估計一個或多個自變量上的因變量的 L1 損失正則化線性回歸模型,并包括顯示跟蹤圖和基于交叉驗證選擇 alpha 超參數值的可選模式。該圖表示該過程的示例輸出。
三、脊(Ridge)
新的線性 ridge 擴展過程估計一個或多個自變量上的因變量的 L2 或平方損失正則化線性回歸模型,并包括用于顯示跟蹤圖和基于交叉驗證選擇 alpha 超參數值的可選模式。該圖表示該過程的示例輸出。
四、參數化加速失效時間 (AFT) 模型
新過程使用非循環壽命數據調用參數化生存模型過程。參數化生存模型假設生存時間服從已知分布,并且此分析擬合加速失效時間模型及其相對于生存時間成比例的模型效應。該圖表示該過程的示例輸出。
五、Pseudo-R2線性混合模型和廣義線性混合模型中的度量
Pseudo-R2度量和類內相關系數現在包含在線性混合模型和廣義線性混合模型輸出中(如果適用)。決定系數 R2是一個經常報告的統計量,因為它表示線性模型解釋的方差比例。類內相關系數 (ICC) 是一種相關統計量,用于量化多級/分層數據中由分組(隨機)因子解釋的方差比例。
六、命令語法
1、GENLINMIXED
輸出現在包括Pseudo-R2度量和類內相關系數(適當時)。
2、LINEAR_ELASTIC_NET
新的擴展命令使用 Python sklearn.linear_model.ElasticNet 類,用于估計一個或多個自變量上因變量的正則化線性回歸模型。
3、LINEAR_LASSO
新的擴展命令使用 Python sklearn.linear_model.Lasso 類,用于估計一個或多個自變量上因變量的 L1 損失正則化線性回歸模型。該命令包括用于顯示跟蹤圖和選擇基于交叉驗證的 alpha 超參數值的可選模式。
4、LINEAR_RIDGE
新的擴展命令使用 Python sklearn.linear_model.Ridge 類,用于估計一個或多個自變量上因變量的 L2 或平方損失正則化線性回歸模型。該命令包括用于顯示跟蹤圖和選擇基于交叉驗證的 alpha 超參數值的可選模式。
5、MIXED
輸出現在包括Pseudo-R2度量和類內相關系數(適當時)。
6、SURVREG AFT
新的擴展命令使用非循環的生命周期數據調用參數化生存模型過程。
7、Python 和R升級
Python 3.10.4 和 R 4.2.0 與 IBM® SPSS® 統計 29 一起安裝。
七、刪除隱藏未選定案例的功能
選擇一部分案例后,未選擇的案例將不再隱藏在數據編輯器中,并且不會丟棄未選擇的案例。這表示返回到Statistics 27.0.1 及更早版本的行為。
八、小提琴圖
圖形板模板選擇器包括一個新的小提琴圖,它是箱形圖和內核密度圖的混合體。小提琴圖顯示數據中的峰值,并用于可視化數值數據的分布。與只能顯示匯總統計數據的箱形圖不同,小提琴圖描述了匯總統計數據和每個變量的密度。
九、工作簿模式增強功能
添加了兩個新的工作簿工具欄項:“顯示/隱藏所有語法窗口”和“清除所有輸出”。狀態欄上還有一個新按鈕,用于在經典(輸出和語法)和工作簿模式之間切換。
十、搜索增強功能
“搜索”功能現在提供了用于直接在工具欄字段中輸入術語以及在下拉窗格中查看結果的選項。
軟件亮點
1、操作簡便
界面非常友好,除了數據錄入及部分命令程序等少數輸入工作需要鍵盤鍵入外,大多數操作可通過鼠標拖曳、點擊“菜單”、“按鈕”和“對話框”來完成
2、編程方便
具有第四代語言的特點,告訴系統要做什么,無需告訴怎樣做。只要了解統計分析的原理,無需通曉統計方法的各種算法,即可得到需要的統計分析結果。對于常見的統計方法,SPSS的命令語句、子命令及選擇項的選擇絕大部分由“對話框”的操作完成。因此,用戶無需花大量時間記憶大量的命令、過程、選擇項
3、功能強大
具有完整的數據輸入、編輯、統計分析、報表、圖形制作等功能。自帶11種類型136個函數。SPSS提供了從簡單的統計描述到復雜的多因素統計分析方法,比如數據的探索性分析、統計描述、列聯表分析、二維相關、秩相關、偏相關、方差分析、非參數檢驗、多元回歸、生存分析、協方差分析、判別分析、因子分析、聚類分析、非線性回歸、Logistic回歸等
4、數據接口
能夠讀取及輸出多種格式的文件。比如由dBASE、FoxBASE、FoxPRO產生的*.dbf文件,文本編輯器軟件生成的ASCⅡ數據文件,Excel的*.xls文件等均可轉換成可供分析的SPSS數據文件。能夠把SPSS的圖形轉換為7種圖形文件。結果可保存為*.txt及html格式的文件
spss29.0 mac版多元logistic回歸分析的使用技巧
一、概述
1、數據
- 這是一份對不同人群早餐選擇的調查數據,通過SPSS的多元回歸分析,可以將人群特征變量對早餐類型進行分析,找到它們之間的關系。
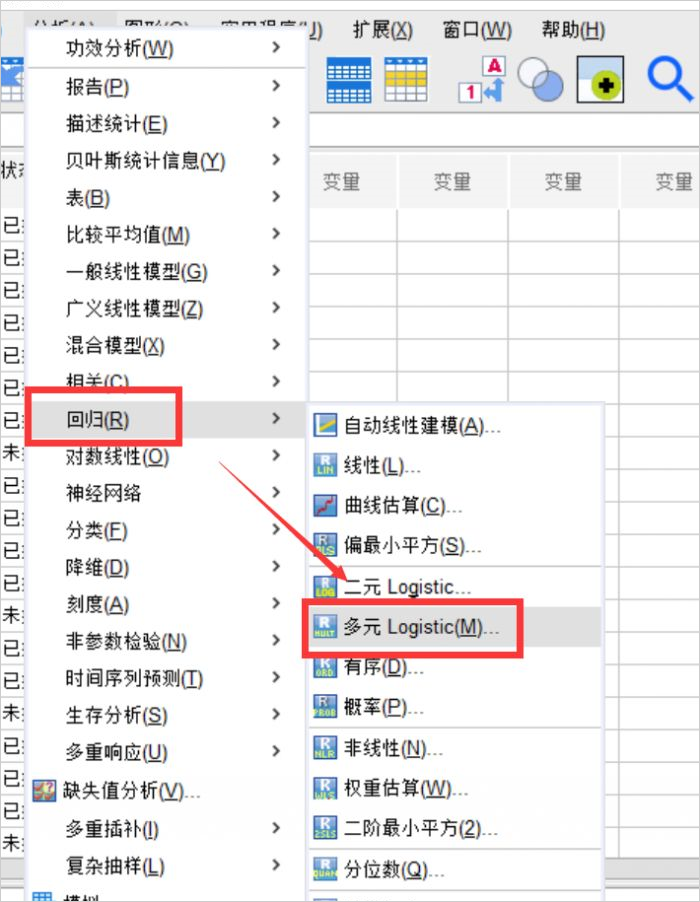
2、功能位置
- 在“分析”菜單下,我們可以找到“回歸”中的“多元logistic”分析,進入多元回歸分析的窗口。
二、分析方法
1、因變量設置
- 因變量就是跟隨自變量變化的量,本例中指的是“首選的早餐”這一變量。
- 點擊“參考類別”,設置因變量的參考類別,這是分析時的參考樣,我們設置為所有類別都和最后一個類別對比,類別順序選擇升序。
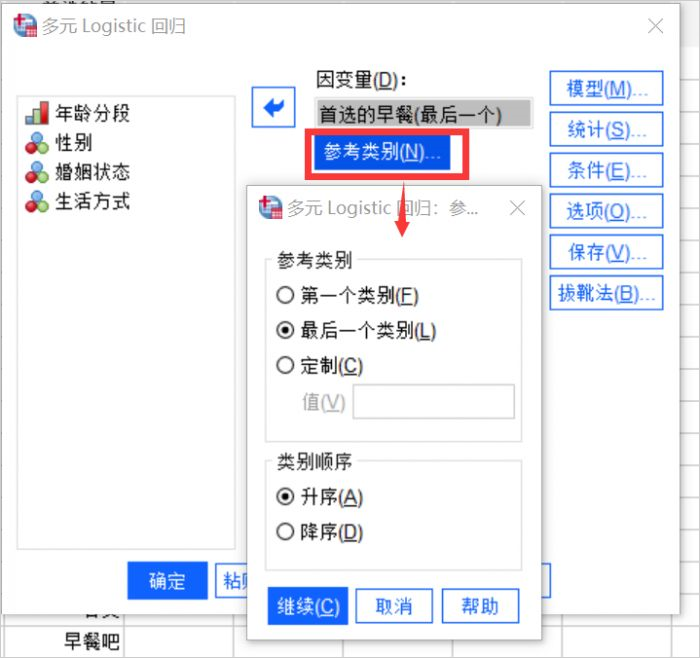
2、因子和協變量
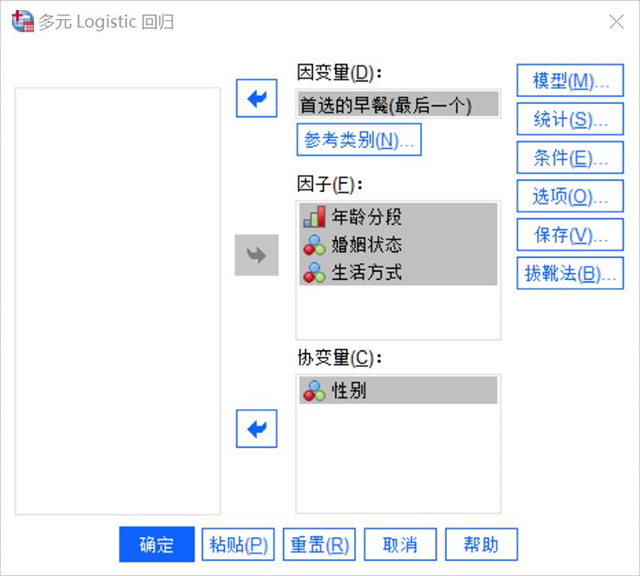
- 因子可以簡單理解為自變量,我們這里將年齡分段、婚姻狀況和生活方式作為因變量處理。
- 協變量是分析過程中需要控制的、對因變量有一定影響的控制變量,這里設置為性別。
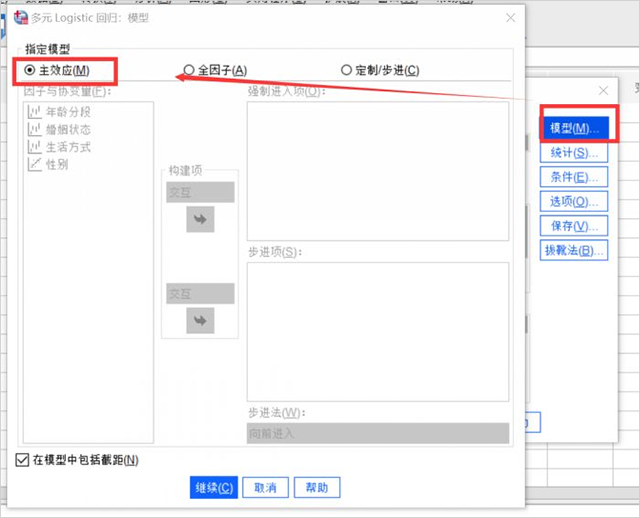
3、分析模型
- SPSS的多元回歸分析有三類模型可選,主效應是指設置好的因子和協變量與因變量之間的關系分析;全因子模型既包括主效應,也包括因子和協變量之間的交互分析;定制步進式則可以有用戶自己定義分析類型。
- 我們這里選擇主效應進行分析即可。
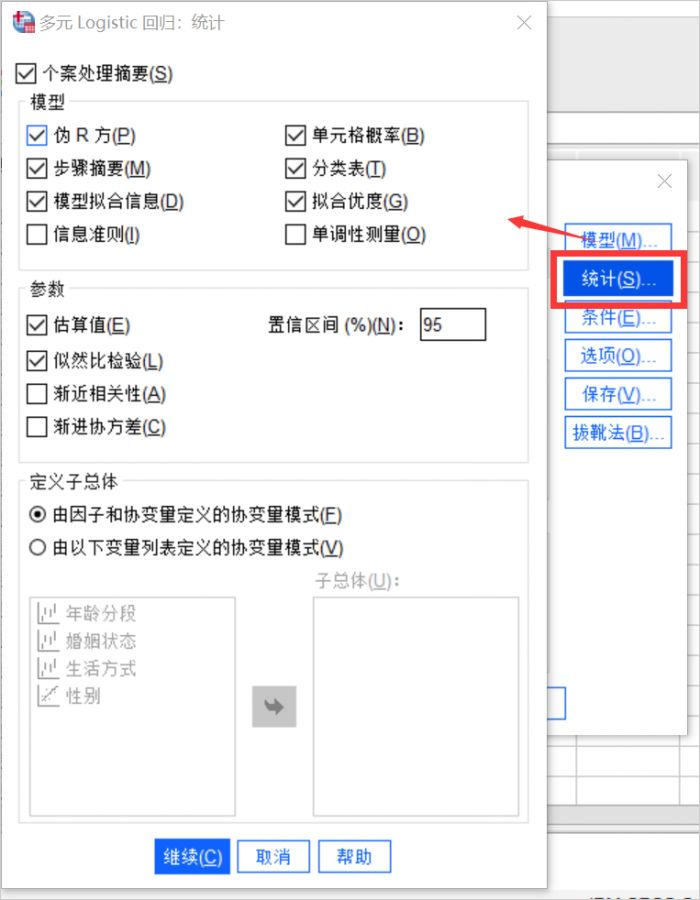
4、統計設置
- 這個窗口內設置的是需要進行的統計數據分析,包括多類統計數據可選,我們勾選模型下的偽R方、單元格可能性、步驟摘要、分類表、模型擬合度信息和擬合度,參數下的估計(置信區間設置為95%)和似然比檢驗。
- 定義子群體選擇“由因子和協變量定義的協變量模式”。
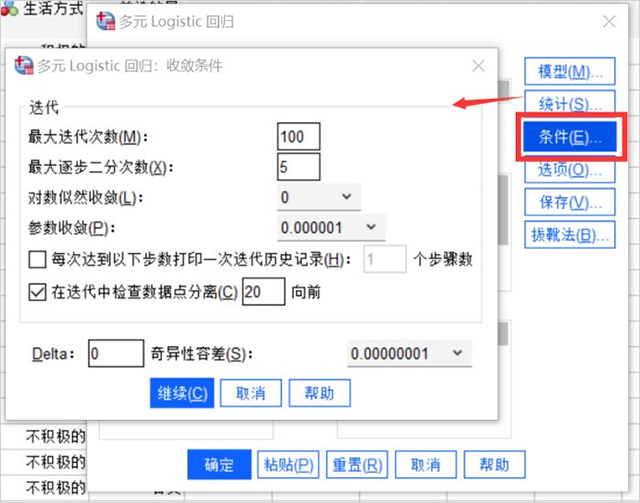
5、收斂條件
- 最大迭代數是數據進行回歸分析時可進行迭代的次數,這個數值必須是大于或小于100的整數,最大步驟對分設置的是迭代時的等分數,系統默認是5。
- 對數似然收斂可設置收斂值,回歸過程中對數似然比函數是大于設定值的;參數收斂的數值設置類似。
- 本例中該對話框保持默認即可。
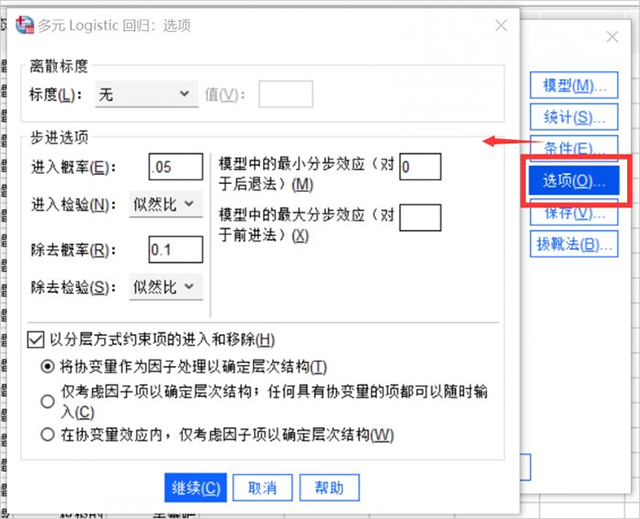
6、選項設置
- 在選項對話框中設置離散度量為“無”。
- 數據的進入概率為0.05,出去概率為0.1,這兩個參數中,前者越大,進入模型的數據越多;后者越小,數據被剔除的越多,進入和出去方法均選擇似然性。
- 其余保持默認即可。
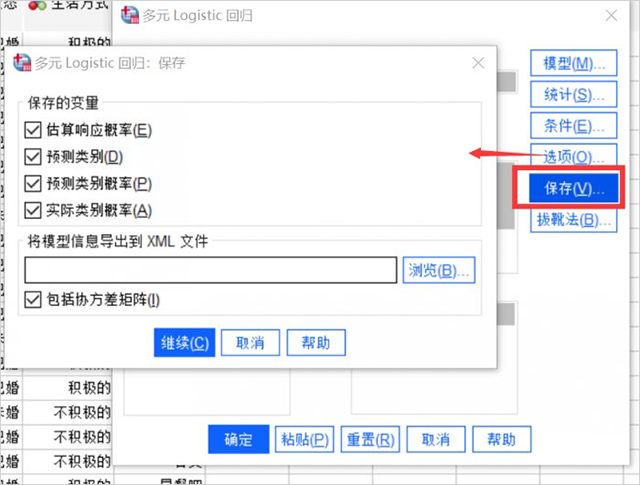
7、保存設置
在這個對話框中設置需要保存的變量,如果需要將模型信息輸出到XML文件,也可以在次設置。
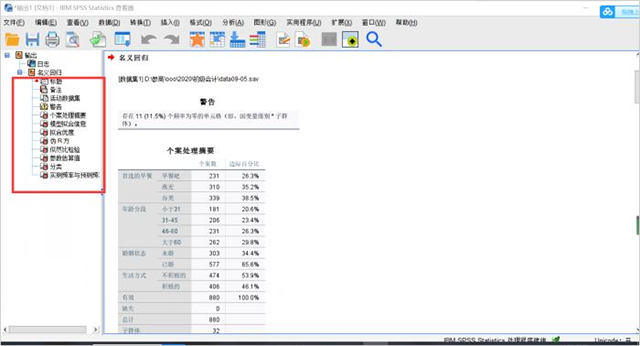
8、完成分析
完成上述設置后,就可以在日志輸出窗口中查看分析結果啦!分析結果包含多個表格,每個數值都有特定含義,大家在分析的時候也要認真觀察數據哦!
spss入門學習使用技巧
一、多項選擇題數據的輸入
方法1:多重二分法。有多少選項就設多少個變量,某個個案選擇了某項則在該變量名下錄入“1”,未選擇某項則錄入“0”,即將每個變量變成類似于“是”、“否”的選擇題。
方法2:多重分類法。有多少選項就設多少個變量,某個個案選擇了某項則在該變量名下錄入“1”,未選擇某項則錄入“0”。例如,某個個案選擇了第“1”、“3”、“4”項, 則依次錄入“1、 0、 1、 1、 0、 0”。
方法3:多重分類法。選了多少項就設置多少個變量,如命名為 seq1、seq2 和 seq3 ,如果某個個案選擇了第“1”、“3”、“2”項時,則依次輸入“1”、“3”、“2”。
方法4:多重分類法,利用Excle的分列功能。
- 設置一個變量,命名為 var1。
- 錄入數據。例如 ,某個個案選擇了第“1、 3、 2”項,則輸入“1 3 2”。
- 將該多選題及其數據另存為 Excle文件。
- 在excle 中將 var1 這一個變量分列 ,步驟是“選定該變量 →數據 →分列 →固定寬度 →下一步→使用鼠標分列 →下一步 →完成。這樣 ,原來的一個變量組成的數據庫轉化為由幾個變量組成的新的數據庫 。
- 將新的變量 Seq1 ,Seq2 ,Seq3 保存。
- 最后 ,使用 SPSS軟件讀取該數據文件
二、分析方法
SPSS提供了三種相關分析方法:
1、Bivariate 方法
- 用于進行兩個/多個變量間的參數/非參數相關分析。如果是多個變量,則給出兩兩相關的分析結果。該方法十分常用 通常會占到所有相關分析的 95%以上。
2、Partial方法
- 用于偏相關分析,通常在進行相關分析的兩個變量其取值均受到其他變量的影響時使用。
3、Distances 方法
- 對同一變量內部各觀察單位間的數值或各個不同變量間進行距離相關分析,在教育教學研究中使用較少。
- 語文成績與數學成績是不是相關?假設采集30 名學生的數學和語文成績進行分析。
- 輸入數據后,對數據的信度進行檢查,并繪制散點圖,直觀查看兩變量間是否有相關性。然后即進行相關分析:
- 在菜單中選擇 Analyze-->Correlate-->Bivariate (即:分析-->相互關系-->二變量),將需要進行分析的變量:數學和語文加入Variables 列表中。
- 在界面中確認選中“ Pearson ”即要求計算皮爾森相關系數,確認選中 Two-tailed ,即要求進行兩邊檢測,選中 Flag significantcorrelations 即當變量間有關時,顯示相關標記,設置完成后 ,單擊OK SPSS 即會幫我們算出結果。