理論奠基:洞悉AI大模型訓練核心原理
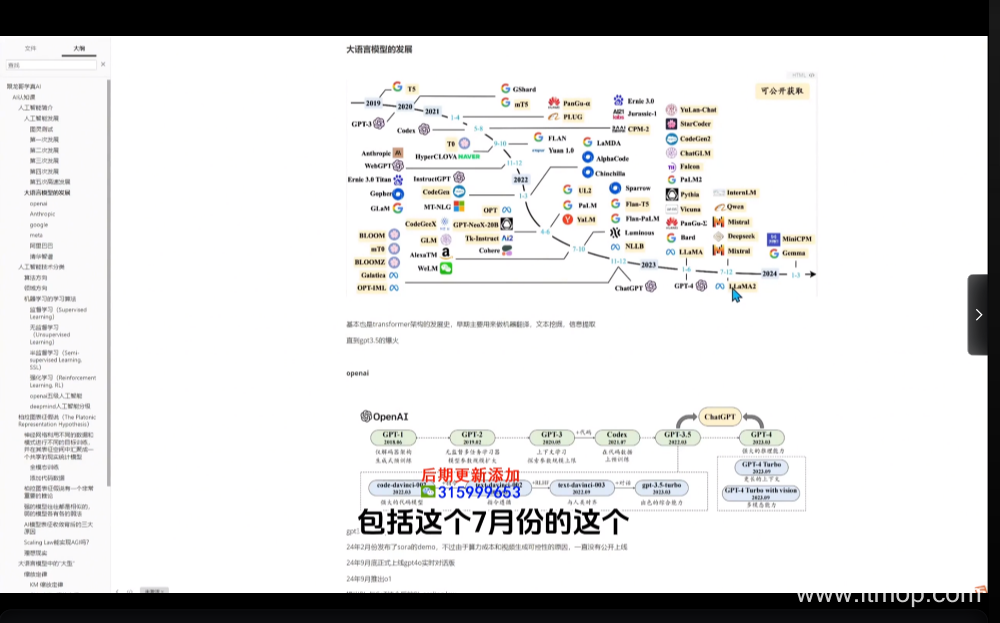
在AI大模型應用開發的征程中,掌握模型訓練的核心原理是首要任務。本教程從基礎理論切入,深入剖析AI大模型的架構,如Transformer架構的精妙設計,以及其在處理序列數據時的卓越表現。詳細講解神經網絡的工作機制,包括神經元如何接收、處理和傳遞信息,以及不同層之間如何協同工作來實現復雜的任務。
同時,對損失函數、優化算法等關鍵概念進行細致解讀,讓學員明白模型如何通過不斷調整參數來最小化損失,從而逼近最優解。通過這些理論知識的傳授,為學員搭建起堅實的認知框架,使他們能夠深入理解模型訓練的本質,為后續的實踐操作奠定理論基礎。
實戰演練:掌握模型訓練全流程技巧
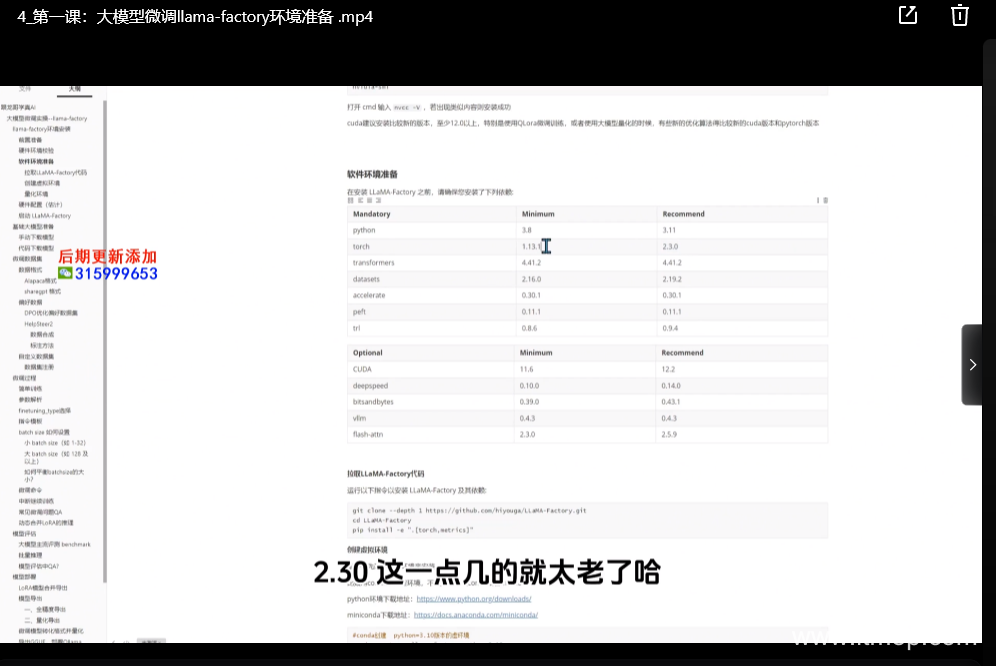
理論學習之后,教程進入實戰演練環節。從數據收集與預處理開始,教授學員如何獲取高質量的數據,并對數據進行清洗、標注和特征工程,以提升模型的訓練效果。接著,詳細介紹如何選擇合適的訓練框架,如PyTorch、TensorFlow等,并演示如何利用這些框架搭建大模型訓練環境。
在模型訓練過程中,講解如何設置超參數、監控訓練進度以及處理過擬合、欠擬合等常見問題。通過實際案例,讓學員親自動手進行模型訓練,從代碼編寫到模型評估,全程參與,熟練掌握模型訓練的全流程技巧。

落地應用:實現AI大模型商業價值轉化
模型訓練完成并非終點,將其成功落地應用才是關鍵。教程聚焦于AI大模型在不同領域的實際應用,如自然語言處理、計算機視覺等,展示如何將訓練好的模型集成到實際業務系統中。講解模型部署的方法與策略,包括云端部署、邊緣端部署等,以及如何進行模型的性能優化和更新維護。
同時,分享如何評估模型在實際應用中的效果,以及如何根據業務需求對模型進行迭代改進。通過這些內容,幫助學員將AI大模型技術轉化為實際的商業價值,推動企業的智能化升級。